How to Run Powerful AI Models Locally on Your Mac (No Internet Required)
The reliance on cloud-based AI services like ChatGPT and Gemini has created a massive dependency on internet connectivity and paid subscriptions. For developers and privacy advocates, sending sensitive code or personal data to a remote server is often a dealbreaker. Fortunately, the hardware inside modern computers, particularly the Apple Silicon chips found in the MacBook Air and Pro, has become powerful enough to run these intelligence models entirely offline. This shift towards "Local AI" is not just a trend; it is a fundamental change in how we interact with software.
Why You Should Go Local
The primary argument for running Large Language Models (LLMs) locally is privacy. When you run a model on your own machine, your data never leaves your local network. You can analyze financial documents, debug proprietary code, or journal your personal thoughts without fear of that data being used to train a corporate model. Beyond privacy, local models offer zero latency. There is no network lag, no queue times, and no censorship. You control the model, the system prompt, and the output parameters.
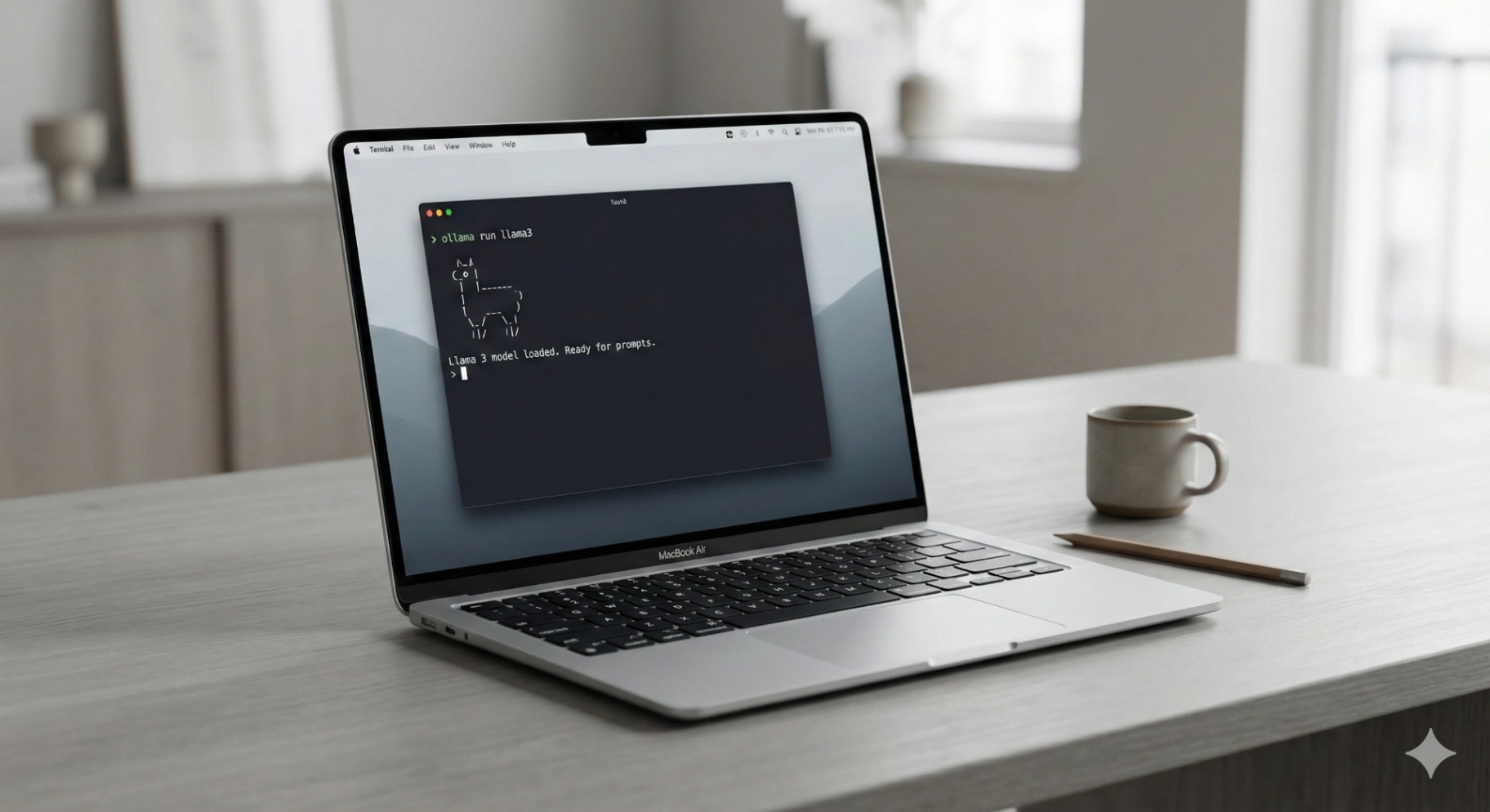
The Tool of Choice: Ollama
While there are many ways to run these models, a tool called Ollama has emerged as the standard for ease of use. It abstracts away the complex Python environments and dependencies usually required to run machine learning models. Instead of spending hours setting up virtual environments, you can simply download the Ollama application, and with a single terminal command, pull down industry-leading models. It optimizes the model automatically for your specific hardware, whether you are running an M1 MacBook Air or a dedicated Linux rig with an NVIDIA GPU.
Choosing the Right Model
Not all models are created equal, and your hardware dictates what you can run. For most users with 8GB or 16GB of unified memory, "quantized" models are the key. Quantization compresses the model weights, slightly reducing precision for a massive gain in performance.
DeepSeek and Llama 3
For general-purpose coding and reasoning, the Llama 3 (8B parameter) model is the current sweet spot. It is incredibly fast and surprisingly coherent. If you are focused on coding specifically, DeepSeek Coder offers exceptional performance in Python and JavaScript generation, often rivaling much larger, paid models. These models typically require only 4GB to 6GB of RAM, leaving plenty of overhead for your operating system.
Integration with Your Workflow
The true power of local AI unlocks when you integrate it into your development environment. Extensions for VS Code allow you to connect directly to your local Ollama instance. This means you can have an AI autopilot completing your code, refactoring your functions, and writing your documentation, all without an internet connection and without paying a cent in API fees. This is the future of development: sovereign, private, and incredibly powerful.



